 Améliorez ce document
Améliorez ce document Créer une issue
Créer une issue Contribuer sur GitHub
Contribuer sur GitHubDonnées primaires sur la biodiversité
| Dans cette section, vous apprendrez comment GBIF rend les données primaires sur la biodiversité accessibles, les types de jeux de données acceptés et comment GBIF utilise l’ossature taxonomique pour fournir des informations taxonomiques. |
Lorsque nous faisons référence aux données primaires sur la biodiversité, nous parlons des données qui documentent où et quand les espèces ont été enregistrées. Ces connaissances proviennent de nombreuses sources, depuis les spécimens de musées collectés aux 18ème et 19ème siècles jusqu’aux photos géolocalisées prises sur des téléphones intelligents par des naturalistes amateurs au cours des derniers jours et des dernières semaines.
Le réseau GBIF rassemble toutes ces sources grâce à l’utilisation de standards de données tels que le Darwin Core, qui est à la base de la majeure partie de l’index de GBIF.org de plusieurs centaines de millions d’enregistrements d’occurrences d’espèces. Les fournisseurs offrent un accès libre à leurs jeux de données en utilisant des licences Creative Commons lisibles par machine, ce qui permet aux scientifiques, aux chercheurs et à d’autres personnes d’impliquer les données dans des centaines de publications évaluées par des pairs et de documents stratégiques chaque année. Nombre de ces analyses - qui couvrent des sujets allant des effets du changement climatique et de la propagation des espèces exotiques envahissantes aux priorités en matière de conservation et de zones protégées, de sécurité alimentaire et de santé humaine - ne seraient pas possibles sans cela.
Classes de jeux de données GBIF
Nous encourageons les détenteurs de données à publier les données les plus riches possibles pour assurer leur utilisation dans un large éventail d’approches et de questions de recherche, mais tous les jeux de données ne comprennent pas des informations avec le même niveau de détail. Le partage de ce qui est disponible sur GBIF.org est précieux, car même des informations partielles répondent à certaines questions importantes.
Les quatre classes de jeux de données prises en charge par le GBIF commencent simplement et deviennent progressivement plus riches, plus structurées et plus complexes.

-
Méta-données seules - jeux de données décrivant des ressources non numérisées comme celles de l’histoire naturelle et d’autres collections
-
Liste taxonomique - un catalogue ou une liste d’organismes nommés, ou taxons
-
Occurrence - la preuve de l'occurrence d’une espèce (ou d’un taxon) à un endroit donné à une date précise. Les jeux de données d’occurrence d’espèces constituent le cœur des données publiées sur GBIF.org
-
Événement d’échantillonnage - offre la preuve qu’une espèce a été présente à un endroit et à une date donnés, mais permettant également d’évaluer la la composition des communautés pour des groupes taxonomiques plus larges ou même l'abondance d’espèces à des moments et des endroits multiples.
Plus d’informations sur les classes de jeux de données peuvent être trouvées sur le site Web du GBIF.
Vous pouvez également explorer comment choisir un type de jeu de données.
Ossature taxonomique du GBIF
Qu’est-ce que l’Ossature taxonomique du GBIF ?
L’Ossature taxonomique est en fait un jeu de données GBIF. Mais pas n’importe quel jeu de données, c’est probablement le jeu de données le plus important pour le GBIF. Sur sa page, il est défini comme :
une classification unique et synthétique dans le but de couvrir tous les noms que le GBIF traite
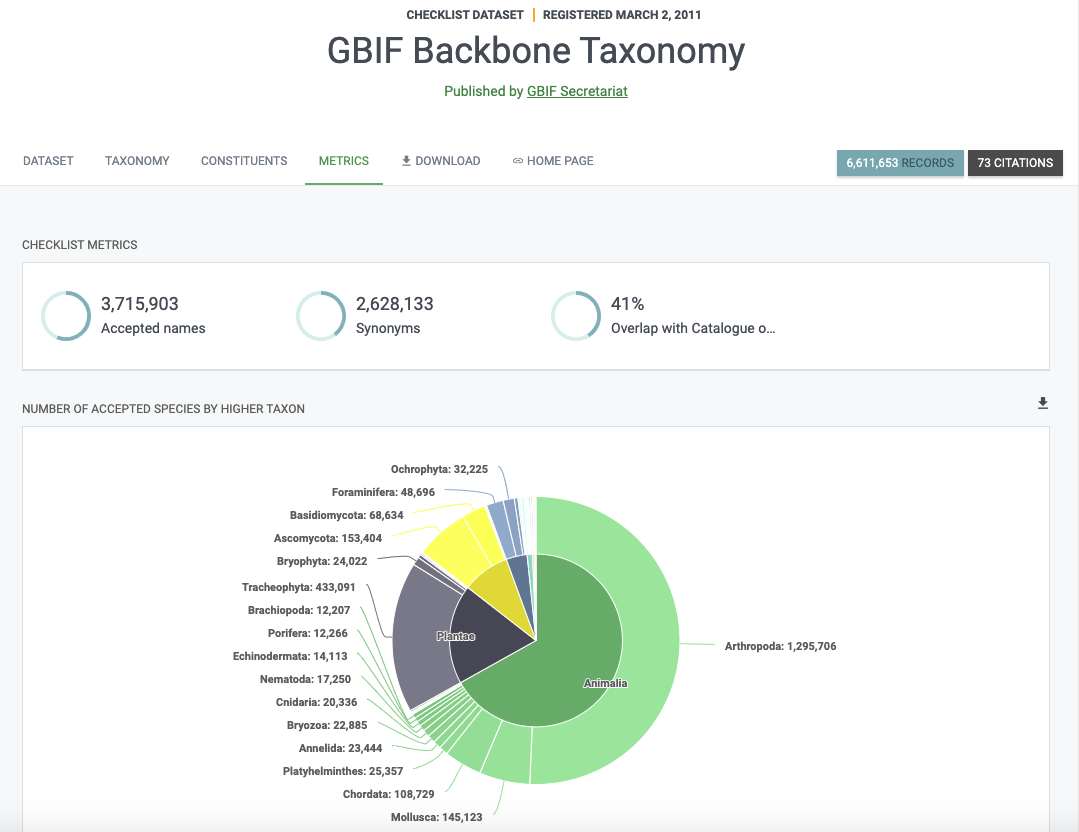
Pourquoi le GBIF a-t-il besoin d’une ossature taxonomique ?
L’ossature taxonomique est nécessaire pour organiser les données disponibles sur GBIF. Sans cela, nous ne serions pas en mesure de faire une recherche taxonomique et il serait difficile de générer des statistiques et des cartes cohérentes.
Comme vous pouvez l’imaginer, tout le monde n’utilise pas les mêmes classifications ou les mêmes noms. Il en résulte des variations considérables dans les taxons supérieurs et un grand nombre de synonymes. L’ossature taxonomique vise à rassembler et à organiser tous ces noms.
Comment l’ossature est-elle générée ?
L’ossature est construite à partir d’autres listes taxonomiques. Celles-ci incluent :
-
55 listes taxonomiques faisant autorité,
-
une liste taxonomique générée à partir de spécimens types partagés sur GBIF,
-
deux sources conséquentes pour des Unités Taxonomiques Opérationnelles (OTUs) stables: les Numéros d’Index des Codes-Barres iBOL et les identifiants d’Hypothèse d’Espèces UNITE,
-
et toutes les listes taxonomiques partagées par PLAZI.org sur GBIF (actuellement 27,054 mais ces listes n’étaient pas toutes disponibles lors de la génération de l’ossature taxonomique).
Ces listes taxonomiques sont classées par ordre de priorité en commençant par le Catalogue of Life pour la plupart des taxons. Cet ordre est crucial car il modèle la taxonomie.
| Notez que de nombreuses occurrences basées sur des séquences génétiques n’ont pas de noms latins, mais sont nommées en utilisant des hypothèses d’espèces (UNITE: champignons) ou des Indices Numériques de Codes-Barres (iBOL : principalement des animaux). C’est pourquoi l’ajout de ces deux principales sources d’OTUs à la dernière version de l’ossature taxonomique améliore considérablement la fonctionnalité d’indexation du GBIF pour les données de biodiversité basées sur des séquences ADN. |
Les informations ci-dessus sont un extrait d’un article blog 2019 de Marie Grosjean. Lisez l’article pour plus de détails sur l’ossature taxonomique.