 Mejora este documento
Mejora este documento Crear una propuesta
Crear una propuesta Editar en GitHub
Editar en GitHubDatos primarios sobre biodiversidad
| En esta sección, aprenderá cómo GBIF hace accesibles los datos primarios de biodiversidad, los tipos de conjuntos de datos aceptados y cómo GBIF utiliza su árbol taxonómico para proporcionar información taxonómica. |
Cuando nos referimos a los datos primarios de biodiversidad, nos referimos a los datos que documentan dónde y cuándo se han registrado las especies. Este conocimiento proviene de muchas fuentes, incluyendo todo desde especímenes de museo recolectados en los siglos XVIII y XIX hasta fotos de teléfonos inteligentes geoetiquetadas compartidas por naturalistas aficionados en los últimos días y semanas.
La red de GBIF reúne todas estas fuentes a través del uso de estándares de datos, como Darwin Core, que constituye la base del índice de GBIF.org de cientos de millones de registros de presencia de especies. Los publicadores proporcionan acceso abierto a sus conjuntos de datos a través de licencias Creative Commons legibles por máquinas, permitiendo a los científicos, investigadores y otras personas usar los datos en cientos de publicaciones revisadas por pares y documentos políticos cada año. Muchos de estos análisis (que abarcan temas que van desde los efectos del cambio climático y la propagación de plagas invasoras y exóticas, hasta las prioridades de conservación y áreas protegidas, la seguridad alimentaria y la salud humana) no serían posibles sin esto.
Tipos de conjuntos de datos
Alentamos a los titulares de datos a que publiquen sus datos de la forma más rica posible para asegurar su uso en una gama más amplia de enfoques y preguntas de investigación, sin embargo, no todos los conjuntos de datos incluyen información con el mismo nivel de detalle. Compartir lo que está disponible a través de GBIF.org es valioso, ya que incluso la información parcial puede responder algunas preguntas importantes.
Las cuatro clases de conjuntos de datos soportados por GBIF comienzan con una estructura simple y se vuelven progresivamente más completos, estructurados y complejos.

-
Solo metadatos: conjuntos de datos que describen recursos no digitalizados como aquellos contenidos en colecciones de historia natural y en otras colecciones
-
Lista de especies ("checklist") - un catálogo o lista de organismos nombrados, o taxones
-
Registros biológicos: la evidencia de la presencia de una especie (u otro taxón) en un lugar concreto en una fecha determinada. Los conjuntos de datos de registros biológicos constituyen la parte central de los datos publicados a través de GBIF.org
-
Evento de muestreo: ofrece evidencia de la presencia de una especie en una determinada ubicación y fecha, pero también permite evaluar la composición de la comunidad para grupos taxonómicos más amplios o incluso la abundancia de especies en múltiples momentos y lugares.
Más información en tipos de conjuntos de datos en el sitio web de GBIF.
También puede explorar cómo elegir un tipo de conjunto de datos .
Árbol taxonómico de GBIF
¿Qué es el árbol taxonómico de GBIF?
El árbol taxonómico es en realidad un conjunto de datos. Pero no es cualquier conjunto de datos, es probablemente el conjunto de datos más importante para GBIF. En su página se define como:
una única clasificación operativa y sintética con el objetivo de cubrir todos los nombres con los que trata GBIF
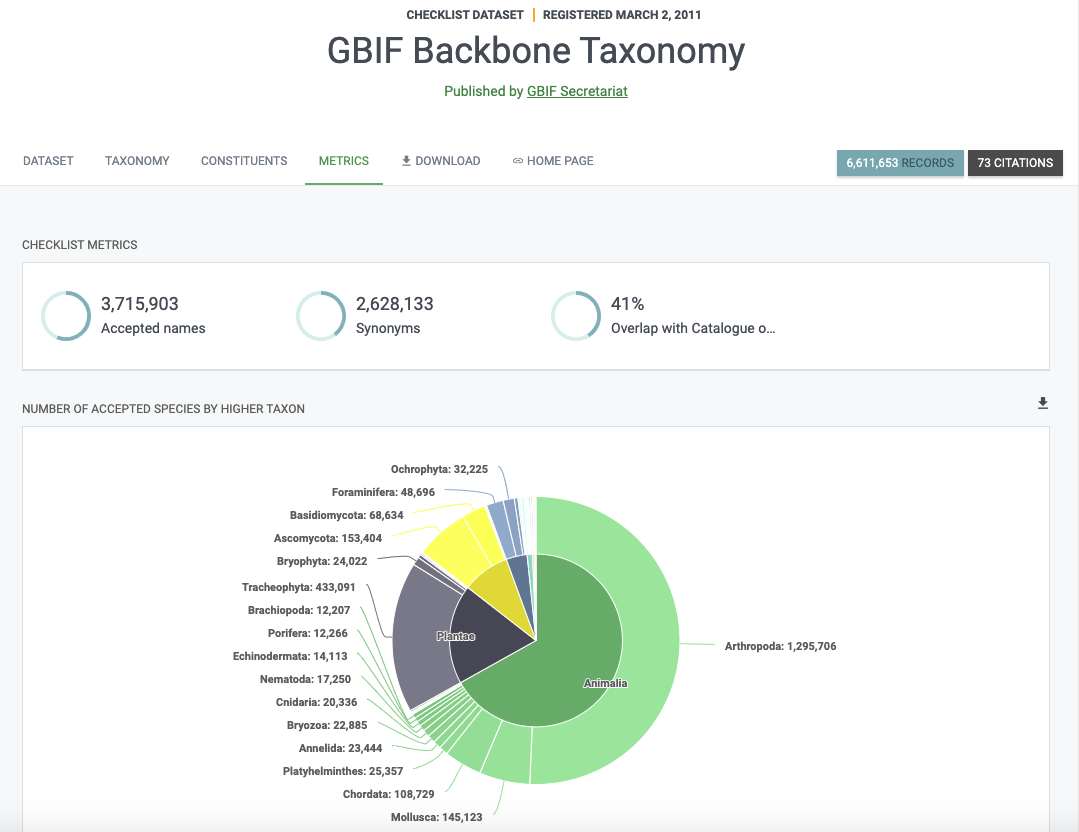
¿Por qué GBIF necesita un árbol taxonómico?
El árbol taxonómico es necesario para organizar los datos disponibles en GBIF. Sin este, no podríamos hacer ninguna búsqueda taxonómica y sería difícil generar estadísticas y mapas coherentes.
Como se puede imaginar, no todos utilizan los mismos nombres o clasificación taxonómica. Esto genera variaciones considerables en lo nombres de los niveles taxonómicos más altos y un gran número de sinónimos. El árbol taxonómico busca reunir todos estos nombres y organizarlos.
¿Cómo se genera el árbol taxonómico?
El árbol taxonómico se construye a partir de otras listas de especies. Estas incluyen:
-
55 listas de autoridades taxonómicas,
-
una lista de especies generada a partir de los especímenes tipo compartidos en GBIF,
-
dos grandes fuentes para "Unidades taxonómicas operativas (OTUs)": iBOL índice de código de barras y UNITE identificadores de hipótesis de especies,
-
y cualquier lista de especies compartida por PLAZI.org en GBIF (actualmente 27,054 pero no todas estas estaban disponibles cuando se generó la última versión del árbol taxonómico).
Estas listas se ordenan por prioridad comenzando con el "Catálogo de vida" para la mayoría de los taxa. Este orden es crucial ya que da forma a la taxonomía del árbol.
| Tenga en cuenta que muchos registros biológicos basados en secuencias no tienen nombres en latín pero son nombradas usando hipótesis de especies (UNITE: hongos) o códigos de barras (iBOL: principalmente animales). Ésa es la razón por la que la adición de estas dos fuentes principales de OTUs estables a la última versión del árbol taxonómico mejora significativamente la funcionalidad de indexación de GBIF para los datos sobre biodiversidad derivados de secuencias. |
La información anterior es un fragmento de una entrada del blog de 2019 de Marie Grosjean. Lea la entrada de blog para obtener más detalles sobre el árbol taxonómico.