 Improve this document
Improve this document Create an issue
Create an issue Edit on GitHub
Edit on GitHubImprove published data quality
| In this section, you will learn how to use the GBIF data validator. |
The GBIF data validator is a service that allows anyone with a GBIF-relevant dataset to receive a report on the syntactical correctness and the validity of the content contained within the dataset. By submitting a dataset to the validator, you can go through the validation and interpretation procedures usually associated with publishing in GBIF and quickly determine potential issues in data - without having to publish it.
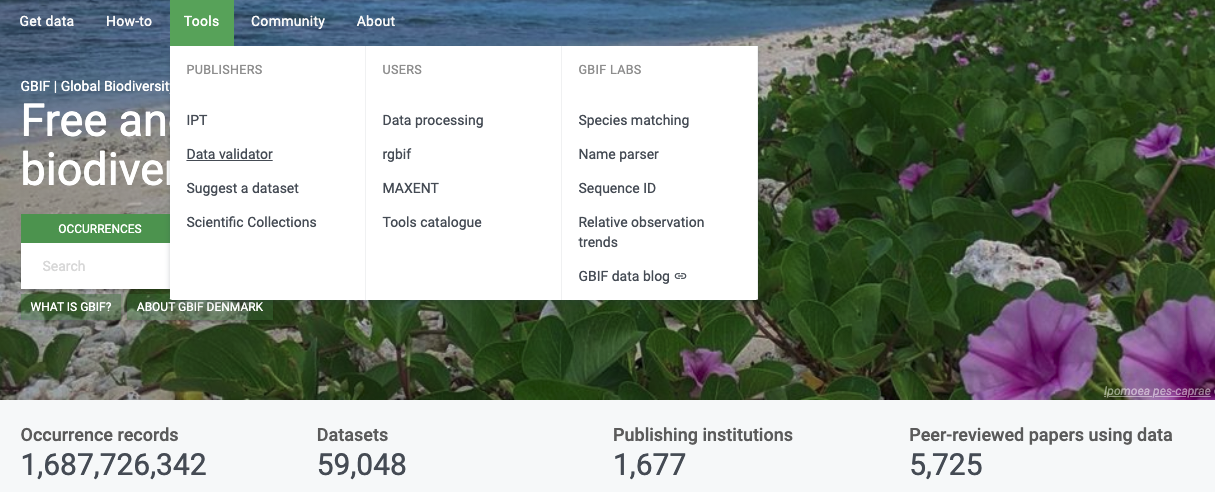
How does it work?
You start by uploading the dataset file to the validator, either by 1) clicking SELECT FILE and selecting it on your local computer or 2) dragging the file from a local folder and dropping it on the Drop here icon. You can also enter the URL of a dataset file accessible from the internet. This is particularly useful for larger datasets. Once you hit the Submit button, the validator starts processing your dataset file. You will be taken straight to a page showing the status of the validation.
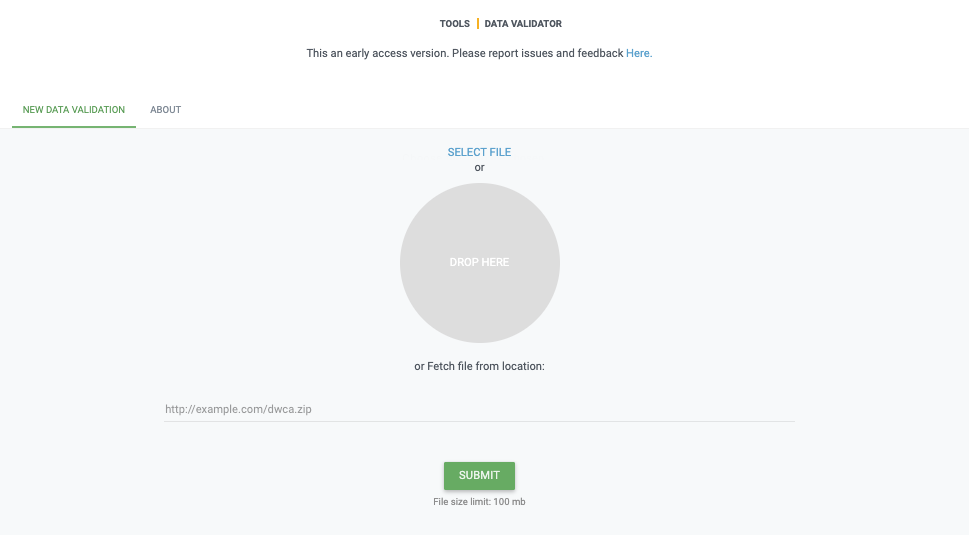
Depending on the size of your dataset, processing might take a while. You don’t have to keep the browser window open, as a unique job ID is issued every time a new validation process is started. If your dataset is taking too long to process, just save the ID (bookmark the URL) and use it to return at a later time to view the report. We’ll keep the report for a month, during which you can come back whenever you like.
Which file types are accepted?
-
ZIP-compressed Darwin Core Archives (DwC-A) (containing cores Occurrence, Taxon, or Event)
-
Integrated Processing Toolkit (IPT) Excel templates containing Checklist, Occurrence, or Sampling-event data
-
Simple CSV files containing Darwin Core terms in the first row
What information is provided from the validation report?
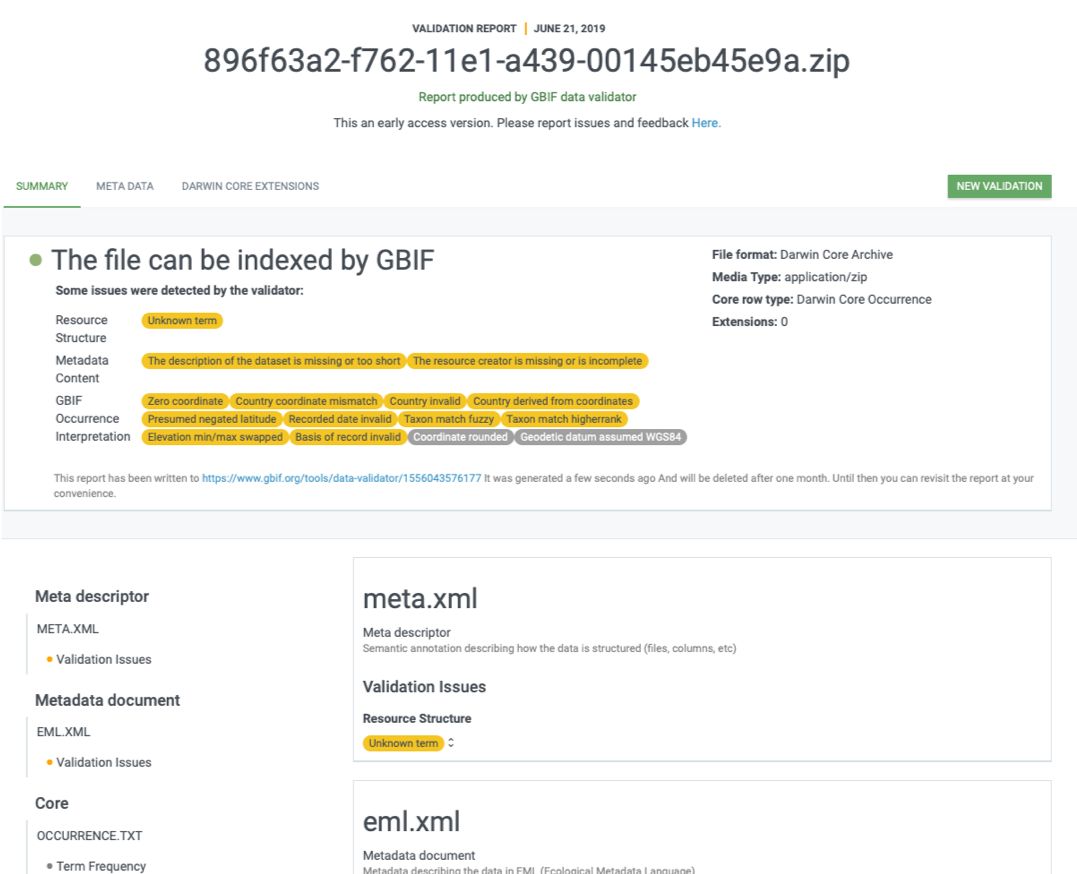
Once processing is done, you will be able to see the validation report containing the following information:
-
a summary of the dataset type and a simple indicator of whether it can be indexed by GBIF or not
-
a summary of issues found during the GBIF interpretation of the dataset
-
detailed break-down of issues found in metadata, dataset core, and extensions (if any), respectively
-
number of records successfully interpreted
-
frequency of terms used in dataset
You will also be able to view the metadata as a draft version of the dataset page as it would appear when the dataset it published and registered with GBIF.
I’ve got the validation report - now what?
If the validator finds that your dataset cannot be indexed by GBIF, you should address the issues raised by the validation report before you consider publishing it to GBIF. Even if your dataset is indexable by GBIF, you should still carefully review any issues that may be the result of e.g. conversion errors, etc. which could affect the quality of the data. If you find and correct any error - from a single typo to large systematic problems - feel free to resubmit your dataset as many times you like.