Improve this document
Improve this document Create an issue
Create an issue Edit on GitHub
Edit on GitHubExercise 6 - Partitioning Occurrence Data
Ideally, you will have two completely independent occurrence datasets to determine the strength of the model’s predictive ability. Unfortunately, this rarely reality. When no independent datasets exist, one solution is to partition your data into subsets we assume are independent of each other, then sequentially build a model on all the subsets but one and evaluate this model on the left-out subset. This is known as k-fold cross-validation (where k is the total number of subsets). After this sequential model- building step is complete, Wallace summarizes (averages) the statistics over all the partitions and builds a consensus model using all the data.
a) Click on “5 Partition Occs” in the browser window in which Wallace is running.
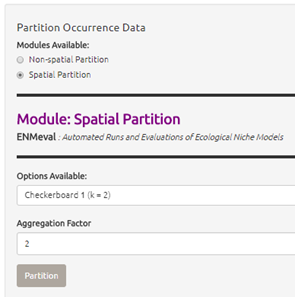
b) Select the “Spatial Partition” radio button.
● From the “Options Available” dropdown menu, select “Checkerboard 1 (k = 2)”.
● Click “Partition”. This may take a few minutes depending on the amount of occurrence data you have and the partition option selected.